可以创建与说话者的嘴唇运动相匹配的合成语音的模型
机器学习模型可以帮助更快、更有效地解决几个现实世界的问题。其中一个问题涉及根据嘴唇的运动为动画角色和人类说话者合成语音。
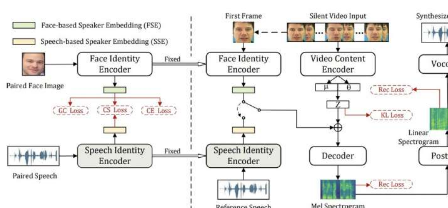
为了解决这个被称为唇语(Lip2Speech)合成的任务,机器学习模型主要学习预测面部和嘴唇运动的特定序列会产生哪些口语词。自动化Lip2Speech合成可用于许多用例,例如帮助无法发出语音的患者与他人交流、为无声电影添加声音、在嘈杂或损坏的视频中恢复语音,甚至用于确定潜在罪犯的声音-更少的闭路电视录像。
虽然Lip2Speech应用程序的一些机器学习取得了可喜的成果,但这些模型中的大多数实时表现不佳,并且没有使用所谓的零样本学习方法进行训练。零样本学习本质上是指预训练模型可以有效地对训练期间未遇到的数据类进行相关预测。
中国科学技术大学的研究人员最近开发了一种新的Lip2Speech合成模型,可以在零样本条件下生成个性化的合成语音。这种方法在arXiv预印本服务器上发表的一篇论文中介绍,它基于变分自动编码器,一种部分基于编码和解码数据的神经网络的生成模型。
为了在零样本条件下有效处理口语语音任务,机器学习模型通常需要从可靠的说话视频记录中提取有关说话者的额外信息。但是,如果只有他们面部说话的无声或难以理解的视频可用,则无法访问此信息。这组研究人员创建的模型可以通过生成与给定说话者的外表和身份相匹配的语音来避免这个问题,而不需要记录说话者的实际语音。
“我们提出了一种零样本个性化Lip2Speech合成方法,其中人脸图像控制说话者的身份,”Zheng-YanSheng、YangAi和Zhen-HuaLing在他们的论文中写道。“采用变分自动编码器来分离说话人身份和语言内容表示,使说话人嵌入能够控制看不见的说话人的合成语音的语音特征。此外,我们提出了相关的跨模态表示学习,以提高基于面部的能力语音控制上的扬声器嵌入(FSE)。”
Sheng、Ai和Ling在一系列测试中评估了他们的模型,发现它表现得非常好,生成的合成语音与说话者的嘴唇运动以及他们的年龄、性别和整体外观相匹配。未来,新模型可用于创建适用于广泛应用的工具,包括为有语言障碍的人提供的辅助应用、视频编辑工具和协助警方调查的软件。
“大量实验证明了所提出方法的有效性,其合成话语比比较方法更自然,更符合输入视频的个性,”Sheng、Ai和Ling说。“据我们所知,本文首次尝试使用人脸图像而不是参考音频来进行零样本个性化Lip2Speech合成,以控制语音特征。”